特定のHTMLソースからタグ情報を除外してテキストのみを抜き出すJavaScriptで、少しハマった部分を備忘録として投稿します。
HTMLから文字列を抽出するスクリプト
結論から示すと、次のスクリプトでHTMLからタグ情報を除外してテキスト(文字)を抜き出すことが可能です。
var html = '<div class="classname"><a href="hogehoge.com">ほげほげ</a></div>';
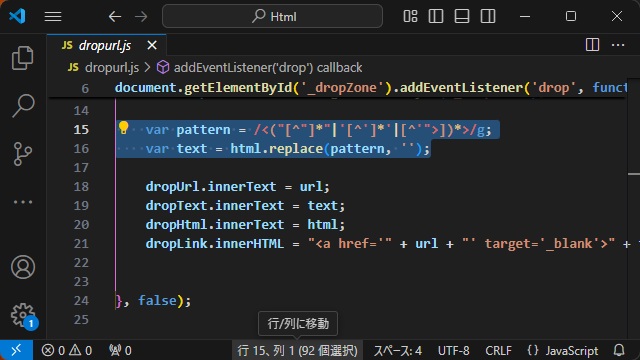
var pattern = /<("[^"]*"|'[^']*'|[^'">])*>/g;
var text = html.replace(pattern, '');重要なのは、正規表現(サンプルコード内の “pattern”変数)の最後の”g”で、合致するパターンが見つかった場合に繰り返し処理されます。
つまり、対象のHTML内に複数のタグがあった場合でも途中で処理が終了することなく最後まで抽出処理が実行されます。
まとめ
今回は短い記事ですが、JavaScript でHTML内のタグを除去してテキストを抽出するスクリプトを紹介しました。
正規表現で処理することが可能ですが、パターンを設定する際に最後に “g” を追加すると繰り返し処理することになり、対象のHTMLに複数のタグが存在した場合でも最後まで処理が継続されます。
正規表現を使って、HTMLからタグ情報を除去したい方の参考になれば幸いです。
スポンサーリンク
最後までご覧いただき、ありがとうございます。